4 Case study: ER injuries
4.1 Introduction
我在过去三章中向您介绍了许多新概念。 因此,为了帮助他们理解,我们现在将介绍一个更丰富的 Shiny app,该 app 探索有趣的数据集并将您迄今为止看到的许多想法汇集在一起。 我们将首先在 Shiny 之外进行一些数据分析,然后将其变成一个 app,从简单开始,然后逐步分层更多细节。
在本章中,我们将用 vroom(用于快速文件读取)和 tidyverse(用于一般数据分析)来补充 Shiny。
4.2 The data
我们将探索来自消费品安全委员会收集的国家电子伤害监控系统 (NEISS) 的数据。 这是一项长期研究,记录了美国代表性医院样本中发生的所有事故。 这是一个值得探索的有趣数据集,因为每个人都已经熟悉该领域,并且每次观察都附有一个简短的叙述,解释事故是如何发生的。 您可以在 https://github.com/hadley/neiss 找到有关此数据集的更多信息。
在本章中,我将只关注 2017 年的数据。 这使数据足够小(~10 MB),以便可以轻松存储在 git 中(以及本书的其余部分),这意味着我们不需要考虑快速导入数据的复杂策略(我们将在本书后面讨论这些策略)。 您可以在 https://github.com/hadley/mastering-shiny/blob/master/neiss/data.R 上查看我用于创建本章摘录的代码。
如果您想将数据传输到您自己的计算机上,请运行以下代码:
dir.create("neiss")
download <- function(name) {
url <- "https://github.com/hadley/mastering-shiny/blob/main/neiss/"
download.file(paste0(url, name), paste0("neiss/", name), quiet = TRUE)
}
download("injuries.tsv.gz")
download("population.tsv")
download("products.tsv")我们将使用的主要数据集是 injuries,其中包含大约 250,000 个观察值:
injuries <- vroom::vroom("neiss/injuries.tsv.gz")
injuries
#> # A tibble: 255,064 × 10
#> trmt_date age sex race body_part diag location prod_code weight
#> <date> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 2017-01-01 71 male white Upper Trunk Contusion O… Other P… 1807 77.7
#> 2 2017-01-01 16 male white Lower Arm Burns, Ther… Home 676 77.7
#> 3 2017-01-01 58 male white Upper Trunk Contusion O… Home 649 77.7
#> 4 2017-01-01 21 male white Lower Trunk Strain, Spr… Home 4076 77.7
#> 5 2017-01-01 54 male white Head Inter Organ… Other P… 1807 77.7
#> 6 2017-01-01 21 male white Hand Fracture Home 1884 77.7
#> # ℹ 255,058 more rows
#> # ℹ 1 more variable: narrative <chr>每行代表一个具有 10 个变量的事故:
trmt_date是该人在医院就诊的日期(不是事故发生的时间)。age、sex和race提供了有关事故发生者的人口统计信息。body_part是身体受伤的位置(例如脚踝或耳朵);location是事故发生的地方(如家或学校)。diag给出损伤的基本诊断(如骨折或撕裂)。prod_code是与伤害相关的主要产品。weight是统计权重,给出了如果将此数据集扩展到美国全体人口时将遭受这种伤害的估计人数。narrative是关于事故如何发生的简短故事。
我们将其与其他两个 data frames 配对以获取更多上下文:products 让我们从产品代码中查找产品名称,population 告诉我们 2017 年每种年龄和性别组合的美国总人口。
products <- vroom::vroom("neiss/products.tsv")
products
#> # A tibble: 38 × 2
#> prod_code title
#> <dbl> <chr>
#> 1 464 knives, not elsewhere classified
#> 2 474 tableware and accessories
#> 3 604 desks, chests, bureaus or buffets
#> 4 611 bathtubs or showers
#> 5 649 toilets
#> 6 676 rugs or carpets, not specified
#> # ℹ 32 more rows
population <- vroom::vroom("neiss/population.tsv")
population
#> # A tibble: 170 × 3
#> age sex population
#> <dbl> <chr> <dbl>
#> 1 0 female 1924145
#> 2 0 male 2015150
#> 3 1 female 1943534
#> 4 1 male 2031718
#> 5 2 female 1965150
#> 6 2 male 2056625
#> # ℹ 164 more rows4.3 Exploration
在创建 app 之前,让我们先探索一下数据。 我们首先来看一个有有趣故事的产品:649, “toilets”。 首先,我们将列出与该产品相关的 injuries:
接下来,我们将对 toilet 相关伤害的位置、身体部位和诊断进行一些基本总结。
请注意,我按 weight 变量进行加权,以便计数可以解释为整个美国的估计总伤害。
selected %>% count(location, wt = weight, sort = TRUE)
#> # A tibble: 6 × 2
#> location n
#> <chr> <dbl>
#> 1 Home 99603.
#> 2 Other Public Property 18663.
#> 3 Unknown 16267.
#> 4 School 659.
#> 5 Street Or Highway 16.2
#> 6 Sports Or Recreation Place 14.8
selected %>% count(body_part, wt = weight, sort = TRUE)
#> # A tibble: 24 × 2
#> body_part n
#> <chr> <dbl>
#> 1 Head 31370.
#> 2 Lower Trunk 26855.
#> 3 Face 13016.
#> 4 Upper Trunk 12508.
#> 5 Knee 6968.
#> 6 N.S./Unk 6741.
#> # ℹ 18 more rows
selected %>% count(diag, wt = weight, sort = TRUE)
#> # A tibble: 20 × 2
#> diag n
#> <chr> <dbl>
#> 1 Other Or Not Stated 32897.
#> 2 Contusion Or Abrasion 22493.
#> 3 Inter Organ Injury 21525.
#> 4 Fracture 21497.
#> 5 Laceration 18734.
#> 6 Strain, Sprain 7609.
#> # ℹ 14 more rows正如您所料,涉及 toilets 的伤害最常发生在 home。 最常见的 body parts 可能表明这些是跌倒(因为 head 和 face 通常不涉及日常厕所使用),并且诊断似乎相当多样化。
我们这里有足够的数据,表格没有那么有用,所以我做了一个图,Figure 4.1,使模式更加明显。
summary <- selected %>%
count(age, sex, wt = weight)
summary
#> # A tibble: 208 × 3
#> age sex n
#> <dbl> <chr> <dbl>
#> 1 0 female 4.76
#> 2 0 male 14.3
#> 3 1 female 253.
#> 4 1 male 231.
#> 5 2 female 438.
#> 6 2 male 632.
#> # ℹ 202 more rows
summary %>%
ggplot(aes(age, n, colour = sex)) +
geom_line() +
labs(y = "Estimated number of injuries")
Figure 4.1: 按 age 和 sex 细分的估计因 toilets 造成的伤害人数
我们看到年轻男孩的数量在 3 岁时达到顶峰,然后从中年左右开始增加(尤其是女性),并在 80 岁之后逐渐下降。 我怀疑这个峰值是因为男孩通常是站着上厕所的,而女性的增加是由于骨质疏松症(即我怀疑女性和男性受伤的比例相同,但更多的女性最终进入急诊室,因为她们骨折的风险更高)。
解释这一模式的一个问题是,我们知道老年人比年轻人少,因此可能受伤的人口也较少。 我们可以通过比较受伤人数与总人口并计算受伤率来控制这一点。 这里我使用的是每 10,000 人的比率。
summary <- selected %>%
count(age, sex, wt = weight) %>%
left_join(population, by = c("age", "sex")) %>%
mutate(rate = n / population * 1e4)
summary
#> # A tibble: 208 × 5
#> age sex n population rate
#> <dbl> <chr> <dbl> <dbl> <dbl>
#> 1 0 female 4.76 1924145 0.0247
#> 2 0 male 14.3 2015150 0.0708
#> 3 1 female 253. 1943534 1.30
#> 4 1 male 231. 2031718 1.14
#> 5 2 female 438. 1965150 2.23
#> 6 2 male 632. 2056625 3.07
#> # ℹ 202 more rows绘制该比率,Figure 4.2,可以得出 50 岁之后的明显不同趋势:男性和女性之间的差异要小得多,而且我们不再看到下降。 这是因为女性往往比男性寿命更长,因此,随着年龄的增长,有更多的女性会因厕所而受伤。
summary %>%
ggplot(aes(age, rate, colour = sex)) +
geom_line(na.rm = TRUE) +
labs(y = "Injuries per 10,000 people")
Figure 4.2: 按 age 和 sex 细分的每 10,000 人估计受伤率
(请注意,该比率仅上升到 80 岁,因为我找不到 80 岁以上的人口数据。)
最后,我们可以看看一些叙述。 浏览这些内容是一种非正式的方式来检查我们的假设,并产生新的想法以供进一步探索。 这里我随机抽取了 10 个样本:
selected %>%
sample_n(10) %>%
pull(narrative)
#> [1] "LUMBAR STR. 19YOM STRAINED LOWER BACK GETTING UP FROM TOILET AT HOME."
#> [2] "77 YO M PT LOST HIS BALANCE FELL OFF THE TOILET ONTO FLOOR HITTING HEADDX CHI"
#> [3] "76 YO M C/O TOE INJURY S/P TRIP AND FALL AND HIT TOE ON BOTTOM OF TOILET DX CLOSED NONDISPLACED FX DISTAL PHALANX LEFT GREAT TOE, FALL"
#> [4] "93YOM WAS TRANSFERRING OFF THE TOILET AT THE NURSING HOME AND LANDED ONTO HEAD CLOSED HEAD INJURY"
#> [5] "7YOF LAC CHIN- FELL OFF TOILET, STRUCK TUB"
#> [6] "25 YOM CUT FINGER ON BROKEN TOILET.DX: FINGER LAC 3 CM."
#> [7] "17 YO F C/O LT BACK PAIN BEGAN AFTER GETTING UP FROM SEATED POSITION ONTOILET DX PROBABLY MUSCLE PAIN"
#> [8] "18 YOM WAS URINATING, PASSED OUT, STRUCK HEAD ON TOILET. NO TRAUMATIC INJURY NOTED. DX VASOVAGAL SYNCOPE"
#> [9] "SCROTUM HEMATOMA. 87YOM FELL AGAINST TOILET BOWL AT HOME."
#> [10] "69YOF GETTING ON HER TOILET AND MISSED IT HIT HEAD ON THE FLOOR CLOSEDHEAD INJURY"在对一个产品进行了这种探索之后,如果我们可以轻松地对其他产品进行此探索,而无需重新输入代码,那就太好了。 那么让我们制作一个 Shiny app 吧!
4.4 Prototype
在构建复杂的 app 时,我强烈建议从尽可能简单的开始,以便您可以在开始做更复杂的事情之前确认基本机制的工作。 在这里,我将从一个 input(product code)、三个 tables 和一个 plot 开始。
在设计第一个原型时,挑战在于使其“尽可能简单”。 快速掌握基础知识和规划 app 的未来之间存在着紧张关系。 任何一个极端都可能是糟糕的:如果你的设计范围太窄,你以后会花很多时间来重新设计你的 app;如果你设计得太严格,你就会花大量时间编写代码,而这些代码最终会被砍掉。 为了帮助实现正确的平衡,我经常在提交代码之前画一些纸笔草图来快速探索 UI 和响应式图。
在这里,我决定为 inputs 设置一行(接受在完成此 app 之前我可能会添加更多输入),为所有三个 tables 设置一行(为每个 table 提供 4 columns,12 column 宽度的 1/3),然后为 plot 设置一行:
prod_codes <- setNames(products$prod_code, products$title)
ui <- fluidPage(
fluidRow(
column(6,
selectInput("code", "Product", choices = prod_codes)
)
),
fluidRow(
column(4, tableOutput("diag")),
column(4, tableOutput("body_part")),
column(4, tableOutput("location"))
),
fluidRow(
column(12, plotOutput("age_sex"))
)
)我们还没有讨论过 fluidRow() 和 column(),但是你应该能够从上下文中猜出它们的作用,我们将在 Section ?? 中回来讨论它们。
另请注意 selectInput() choices 中 setNames() 的使用:这会在 UI 中显示产品名称并将产品代码返回到 server。
server 函数相对简单。
我首先将上一节中创建的 selected 变量和 summary 变量转换为响应式表达式。
这是一个合理的一般模式:您在数据分析中创建变量以将分析分解为步骤,并避免多次重新计算,并且响应式表达式在 Shiny apps 中发挥相同的作用。
通常,在启动 Shiny app 之前花一点时间清理分析代码是个好主意,这样您就可以在添加额外的响应式复杂性之前在常规 R 代码中考虑这些问题。
server <- function(input, output, session) {
selected <- reactive(injuries %>% filter(prod_code == input$code))
output$diag <- renderTable(
selected() %>% count(diag, wt = weight, sort = TRUE)
)
output$body_part <- renderTable(
selected() %>% count(body_part, wt = weight, sort = TRUE)
)
output$location <- renderTable(
selected() %>% count(location, wt = weight, sort = TRUE)
)
summary <- reactive({
selected() %>%
count(age, sex, wt = weight) %>%
left_join(population, by = c("age", "sex")) %>%
mutate(rate = n / population * 1e4)
})
output$age_sex <- renderPlot({
summary() %>%
ggplot(aes(age, n, colour = sex)) +
geom_line() +
labs(y = "Estimated number of injuries")
}, res = 96)
}请注意,创建响应式 summary 在这里并不是绝对必要的,因为它仅由单个响应式使用者使用。
但最好将计算和绘图分开,因为这样可以使 app 的流程更容易理解,并且在将来更容易推广。
生成的 app 的屏幕截图如 Figure 4.3 所示。 您可以在 https://github.com/hadley/mastering-shiny/tree/main/neiss/prototype.R 找到源代码,并在 https://hadley.shinyapps.io/ms-prototype/ 尝试该 app 的实时版本。
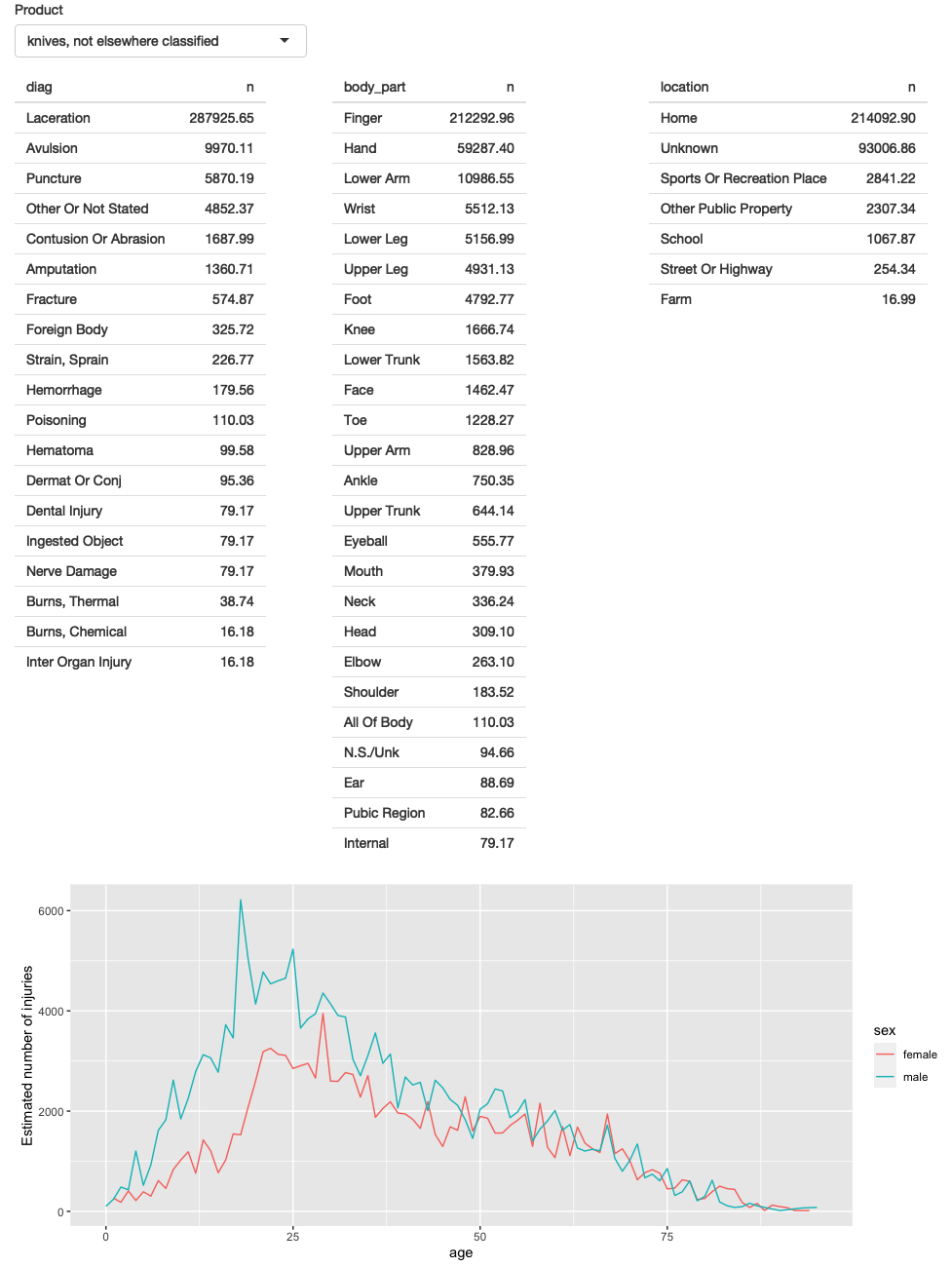
Figure 4.3: NEISS 探索 app 的第一个原型
4.5 Polish tables
现在我们已经具备了基本组件并可以运行,我们可以逐步改进我们的 app。 这个 app 的第一个问题是它在表格中显示了大量信息,而我们可能只需要突出显示。 为了解决这个问题,我们需要首先弄清楚如何截断表。 我选择使用 forcats 函数的组合来实现这一点:我将变量转换为一个 factor,按 levels 的频率排序,然后将前 5 个级别之后的所有 levels 集中在一起。
injuries %>%
mutate(diag = fct_lump(fct_infreq(diag), n = 5)) %>%
group_by(diag) %>%
summarise(n = as.integer(sum(weight)))
#> # A tibble: 6 × 2
#> diag n
#> <fct> <int>
#> 1 Other Or Not Stated 1806436
#> 2 Fracture 1558961
#> 3 Laceration 1432407
#> 4 Strain, Sprain 1432556
#> 5 Contusion Or Abrasion 1451987
#> 6 Other 1929147因为我知道如何做到这一点,所以我编写了一个小函数来自动处理任何变量。 细节在这里并不重要,但我们将在 Chapter ?? 中再次讨论它们。 您还可以通过复制和粘贴来解决问题,因此不必担心代码看起来完全陌生。
count_top <- function(df, var, n = 5) {
df %>%
mutate({{ var }} := fct_lump(fct_infreq({{ var }}), n = n)) %>%
group_by({{ var }}) %>%
summarise(n = as.integer(sum(weight)))
}然后我在 server 函数中使用它:
output$diag <- renderTable(count_top(selected(), diag), width = "100%")
output$body_part <- renderTable(count_top(selected(), body_part), width = "100%")
output$location <- renderTable(count_top(selected(), location), width = "100%")我做了另一项更改来提高 app 的美观性:我强制所有表格占据最大宽度(即填充它们出现的列)。 这使得输出更加美观,因为它减少了附带变化的量。
生成的 app 的屏幕截图如 Figure 4.4 所示。 您可以在 https://github.com/hadley/mastering-shiny/tree/main/neiss/polish-tables.R 找到源代码,并在 https://hadley.shinyapps.io/ms-polish-tables 尝试该 app 的实时版本。
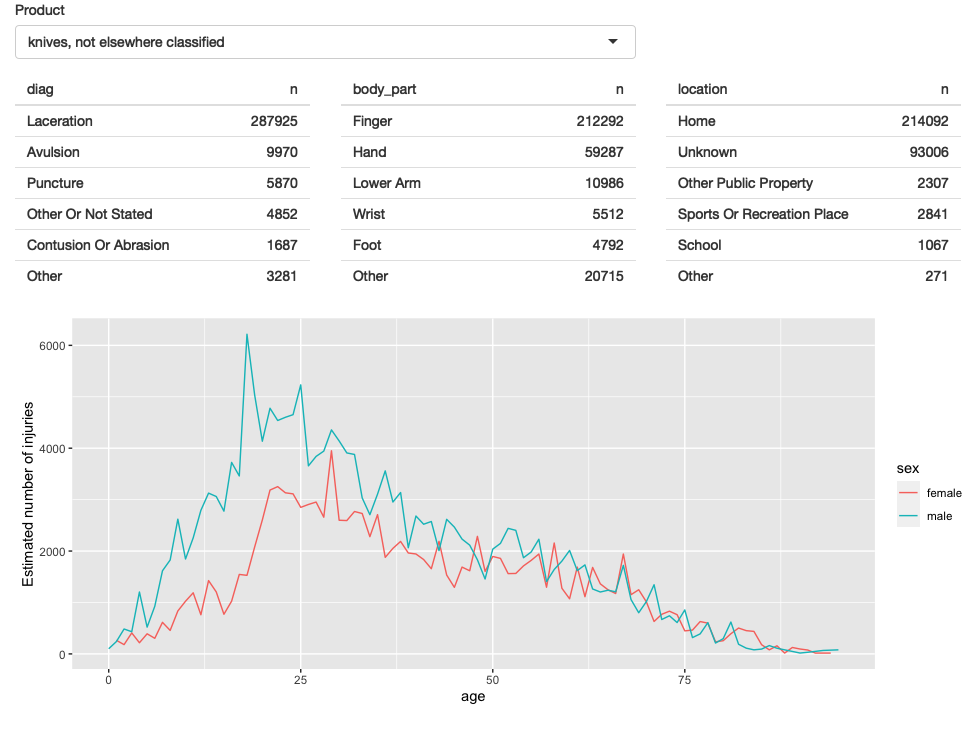
Figure 4.4: app 的第二次迭代通过仅显示汇总表中最常见的行来改进显示
4.6 Rate vs count
到目前为止,我们只显示了一个图,但我们希望用户可以选择是可视化受伤人数还是人口标准化率。
首先,我向 UI 添加一个控件。
这里我选择使用 selectInput() 因为它使两种状态都明确,并且将来添加新状态会很容易:
fluidRow(
column(8,
selectInput("code", "Product",
choices = setNames(products$prod_code, products$title),
width = "100%"
)
),
column(2, selectInput("y", "Y axis", c("rate", "count")))
),(我默认为 rate,因为我认为这样更安全;您不需要了解人口分布即可正确解释该图。)
然后我在生成绘图时以该输入为条件:
output$age_sex <- renderPlot({
if (input$y == "count") {
summary() %>%
ggplot(aes(age, n, colour = sex)) +
geom_line() +
labs(y = "Estimated number of injuries")
} else {
summary() %>%
ggplot(aes(age, rate, colour = sex)) +
geom_line(na.rm = TRUE) +
labs(y = "Injuries per 10,000 people")
}
}, res = 96)生成的 app 的屏幕截图如 Figure 4.5 所示。 您可以在 https://github.com/hadley/mastering-shiny/tree/main/neiss/rate-vs-count.R 找到源代码,并在 https://hadley.shinyapps.io/ms-rate-vs-count 上尝试该 app 的实时版本。
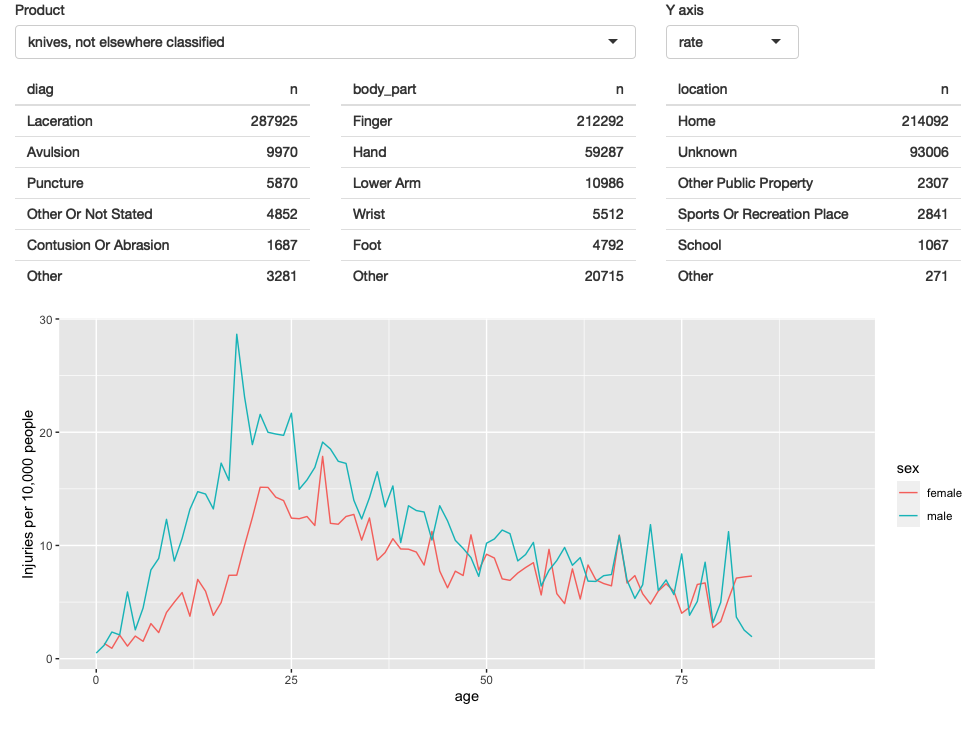
Figure 4.5: 在此迭代中,我们使用户能够在 y 轴上显示计数或人口标准化率之间进行切换。
4.7 Narrative
最后,我想提供一些访问叙述的方式,因为它们非常有趣,并且它们提供了一种非正式的方式来交叉检查您在查看绘图时提出的假设。 在 R 代码中,我一次采样多个叙述,但没有理由在可以交互式探索的 app 中这样做。
解决方案有两个部分。
首先,我们在 UI 底部添加一个新行。
我使用 action button 触发新故事,并将叙述放入 textOutput() 中:
fluidRow(
column(2, actionButton("story", "Tell me a story")),
column(10, textOutput("narrative"))
)然后,我使用 eventReactive() 创建一个响应,仅在单击按钮或底层数据更改时更新。
narrative_sample <- eventReactive(
list(input$story, selected()),
selected() %>% pull(narrative) %>% sample(1)
)
output$narrative <- renderText(narrative_sample())生成的 app 的屏幕截图如 Figure 4.6 所示。 您可以在 https://github.com/hadley/mastering-shiny/tree/main/neiss/narrative.R 找到源代码,并在 https://hadley.shinyapps.io/ms-narrative 尝试该 app 的实时版本。
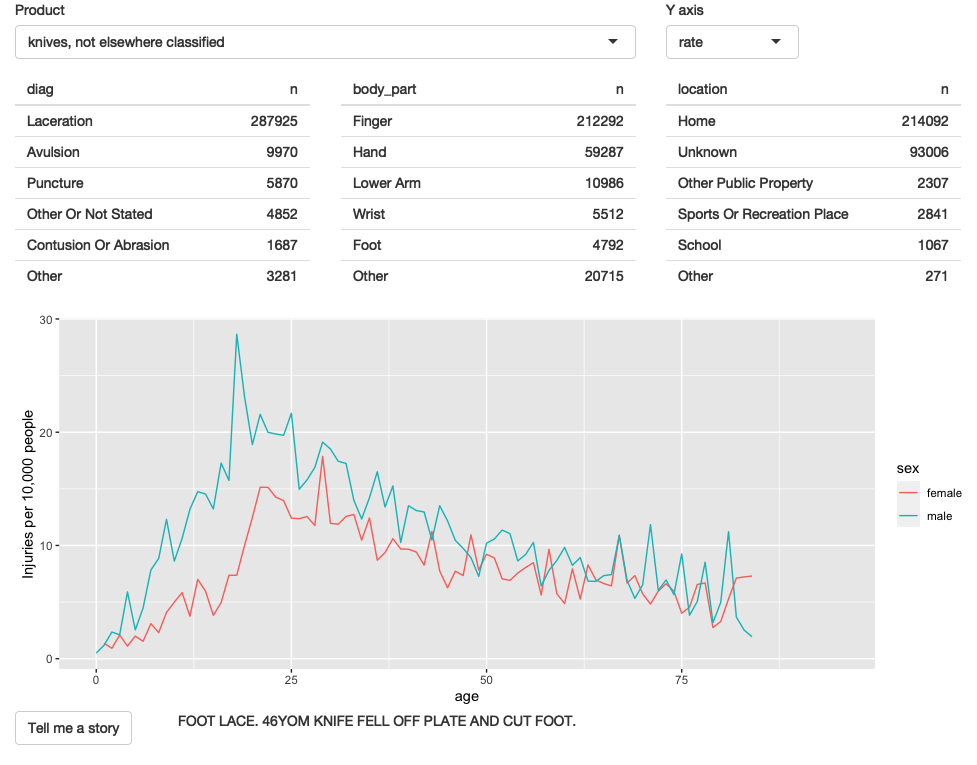
Figure 4.6: 最终迭代增加了从所选行中提取随机叙述的能力
4.8 Exercises
绘制每个 app 的响应式图。
如果在减少汇总表格的代码中翻转
fct_infreq()和fct_lump()会发生什么?添加一个输入控件,让用户决定在汇总表中显示多少行。
-
提供一种通过前进和后退按钮系统地逐步浏览每个叙述的方法。
Advanced:将叙述列表设为 “circular”,以便从最后一个叙述前进到第一个叙述。